【捣腾】AI工具探索:音频处理
【教程】AI工具探索:音频处理
【音轨分离】伴奏提取工具Spleeter
Spleeter是一款由法国流媒体公司Deezer开发的开源音轨分离工具,可将已经混音的音乐按人声与不同乐器拆分成包括人声、钢琴等的最多5个音轨。据测评,效果虽然不及原版单音轨文件(必然的),但是吊打传统的Au中置声道提取法,完全满足日常翻唱、制作背景音乐等需求。
Spleeter的工作原理是基于Python和Tensorflow实现的机器学习,通过预训练的模型对输入的音频进行分析并运算,从而达到分离的目的。
原生的Spleeter基于代码交互,需要在命令行中进行操作,对非计算机行业的朋友较不友好。因此有人开发出了图形版本的工具,并且自带核心,下载安装即可使用。以下是一些相关链接,感谢开发者们的付出🥰🥰
源项目地址: https://github.com/deezer/spleeter/
SpleeterGUI(图形版): https://makenweb.com/SpleeterGUI
以下是我在写作时参考了的一篇相关教程,写得相当详细!感谢!
参考文章: 伴奏提取神器spleeter探索记 - 知乎
Spleeter的安装
对于运行在Python上的项目,安装配置时建议使用Conda的虚拟环境,避免各种版本冲突。
打开配置好Anaconda了的终端,分步运行以下内容:
1 | 创建虚拟环境: prefix参数后是你需要配置环境的路径. |
注意,官方并不推荐使用conda命令安装Spleeter,容易出现不兼容等问题。
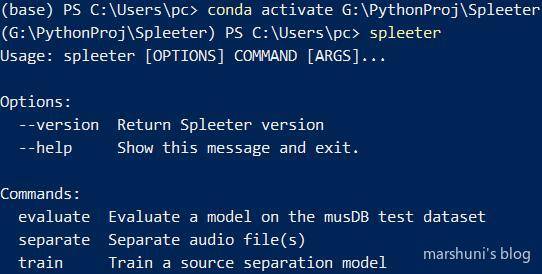
若最后一步操作出现”Successfully installed”字样,
且此时在命令行输入spleeter,出现以下内容,则表示已经安装完成
疑难解答
- 使用pip安装时,若出现下载速度慢的问题,可在
install后附带参数-i https://pypi.tuna.tsinghua.edu.cn/simple,表示从国内镜像源下载模块。
Spleeter的使用
直接在命令行中使用spleeter即可。命令语法如下:
spleeter separate -p [使用的模型] -o [输出路径] [目标音频路径文件名]
例: spleeter separate -p spleeter:2stems-finetune -o .\Output 'C:\Users\pc\Desktop\Beyond - 海阔天空.mp3'
- 若路径中文件名或文件夹包含空格,则需要用英文双引号将路径名括起来。
-p后接本次分离使用的模型。一般使用内置的预训练模型即可。- 若只需分离人声+伴奏双音轨,则
-p后接spleeter:2stems; - 若需要分离人声+鼓点+贝斯+其他音轨,则
-p后接spleeter:4stems - 若需要分离人声+钢琴+鼓+贝斯+其他共5个音轨,则
-p后接spleeter:5stems(效果相对一般)
- 若只需分离人声+伴奏双音轨,则
首次运行:下载预训练模型
第一次运行spleeter命令时,会从自动Github下载预训练的模型:
INFO:spleeter:Downloading model archive https://github.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz
但由于国内访问Github的稳定性堪忧,很容易出现下载失败的问题。此时不妨自行访问Github网站下载预训练模型。
下载完毕后,解压放在当前运行目录(终端当前路径)下的pretrained_models的对应文件夹中。例如,若下载的是2stems.tar.gz,则把压缩包内文件解压后放在.\pretrained_models\2stems文件夹中。
此外,若出现Can't load save_path when it is None报错,也是因为预训练模型没有下载完导致的。
使用体会
我使用了 Beyond的《海阔天空》 和 Queen乐队的《Under Pressure》 来测试工具效果(2stems模型)。
并没有特意使用GPU版本的Tensorflow, 纯使用CPU分析的速度稍微慢一点,但也只花了20秒左右的时间。

最终生成的伴奏和人声有着相当不错的效果,但并没有到出乎意料的程度。其中人声可能是因为混响以及后期处理的原因,分离之后听起来有些怪怪的,有一种在浴室里唱歌的感觉。同时也存在不少电音的问题,普通人一眼(?)就能听出来,并不适合专业用途,只能拿来玩玩。
但是去除人声的伴奏效果则非常完美,至少比我听过的大多数KTV伴奏质量要高。猜测是因为这部分音频是直接用原音频“减去”AI提取出的人声得到的,所以效果更好。
【音轨分离】伴奏提取工具Ultimate Vocal Remover GUI
这款工具本身就是GUI版本的!即下即用!
源仓库地址:https://github.com/Anjok07/ultimatevocalremovergui
下载地址:https://github.com/Anjok07/ultimatevocalremovergui/releases
相比于上面的Spleeter,UVR发展得更为完善,使用体验也更好,据说是当前最完美的解决方案。
美中不足的是它对电脑的配置要求相对更高,但瑕不掩瑜。
以下是大致的配置要求。
最低配置:NVIDIA GeForce GTX 1060 6GB
推荐配置:拥有至少8GB显存的NVIDIA显卡,不支持AMD显卡
相比于上面的Spleeter,安装流程简单了很多,只需要下载安装包(1.56G),打开安装即可。安装大概会占用5GB硬盘空间。
UVR的使用
傻瓜式的操作
软件界面如下。只需选择输入文件与输出目录,并在CHOOSE MDX-NET MODEL处选择默认模型,单击Start Processing 即可开始分析转换工作。
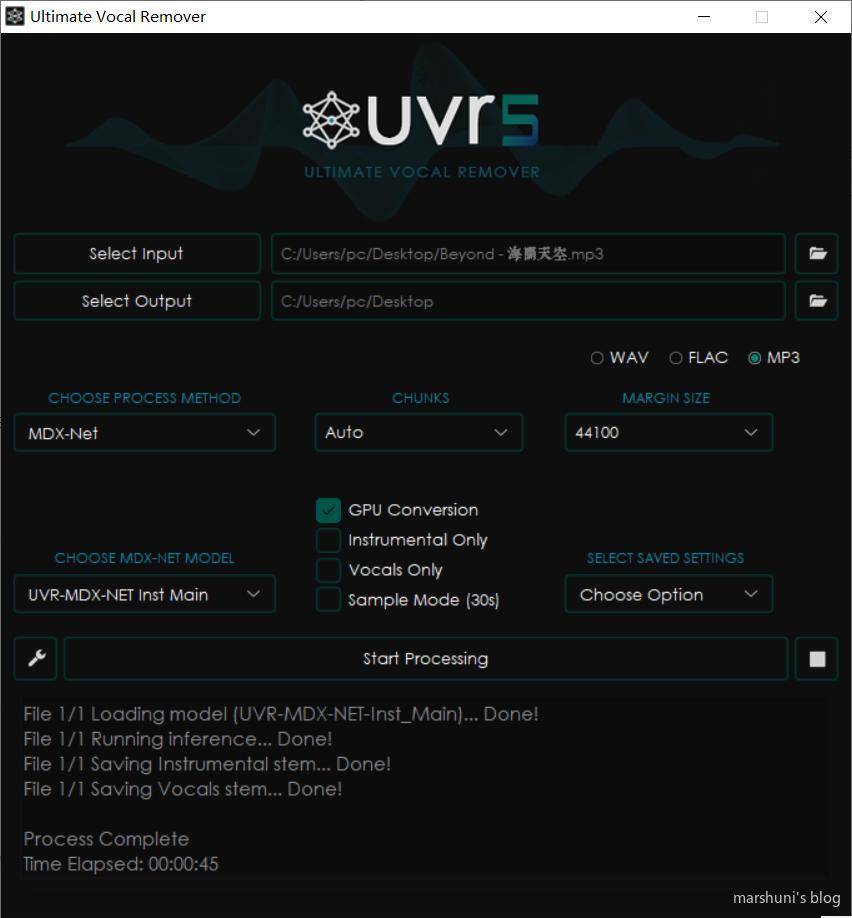
实测在使用1060 6GB显卡的情况下,处理 《海阔天空》 的用时为45s,期间显存最高占用5.7G,可以说是勉强足够完成任务。
而在输出效果上,伴奏轨和Spleeter相差无几,都可以说是无限接近原版的完美程度(至少我听不出orz)。而操作上UVR更为简单,因此略胜一筹。实在要挑刺的话,我在UVR导出的伴奏听到了一些细微的人声泄漏,大致在某一句的尾音部分,一般很难察觉。
UVR导出的人声轨则完胜Spleeter。声音失真的问题几乎完全解决,甚至连和声部分也较为完整地提取了出来(偶尔时断时续),虽然有时能在一句的末尾或间奏时听到一些伴奏,但已经不影响正常使用了。
以及这时我才察觉到Spleeter人声提取中的下水道效果是由于和声混到一起导致的。
综上,在没有电脑配置限制的情况下,强烈推荐UVR!!
【文本转语音】AI拟声ElevenLabs
ElevenLabs是一个闭源的在线工具,可以将输入的英语文本转化为语音,即我们常说的文本转语音(TTS)。但与我们常见的文本转语音系统不同的是,这款工具生成的声音非常逼真,无论是从断句和停顿的角度,还是对文本感情的把握,这款拟声模型都做到了几乎完美的程度。
不足之处是该模型只支持英语文本。即使目前我们没有制作英语配音视频的需求,但我们也可以拿它来练习听力和口语(?
闭源的工具必然也会有收费的部分,但这个公司良心地提供了免费套餐。目前官网提供了每月10000字语音生成的免费额度。而且订阅“初学者”套餐也并不是太贵,$5每月,并且有首月优惠。如果的确有这方面需求的同学可以考虑。
生成语音
注册登录进入网站后(需要科学),在Speech Synthesis栏目下输入需要转化为语音的文本,并在上方的设置中调整参数,即可生成一段语音了。
其中第一栏可以选择声线,网站内置了9种声线,同时也支持使用自己定制的声线。
在Voice Settings中可以调整待输出声音的参数。
Stability: 调整输出语音的稳定性,较低的稳定性拥有更大的感情起伏和张力,但也可能导致声音不稳定;稳定性越高,则输出的声音愈发冷静严肃,但也有可能导致过于单调。Clarity + Similarity Enhancement: 纯净度和相似性增强。这个滑块用于调整声音的纯净度与清晰度,但过高的参数也可能导致声音失真,因此需要酌情调节。
使用界面如图。
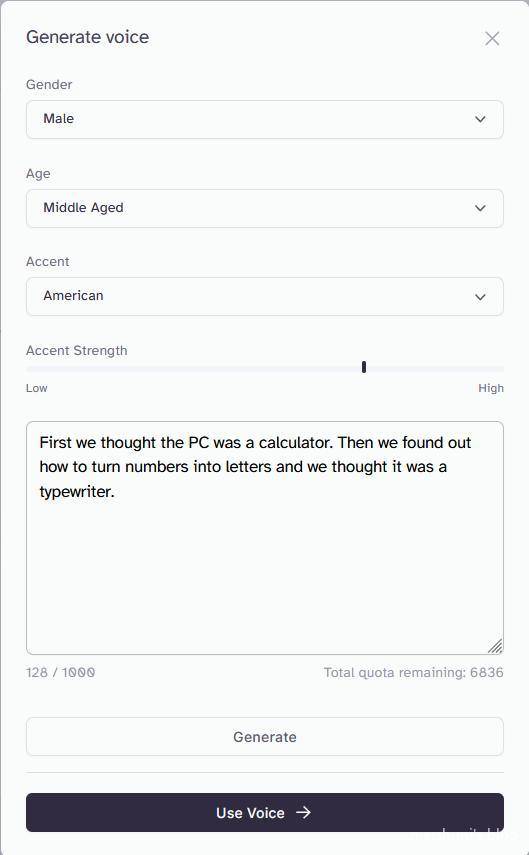
我尝试使用马丁·路德金的《我有一个梦想》经典片段来生成语音。
……
我的评价是……相当……惊艳!
从没听过感情这么丰富的AI拟声,生成出的短短50秒音频中,一个年轻的男声从平淡地叙述到逐渐慷慨激昂,到中间甚至出现了一些哭腔,再到最后逐渐趋于凝重和低沉。停顿也处理得很到位,到后面和原版音频都没有太大的出入,以至于我怀疑它的训练集里面是不是有这一段文稿。
但可能是Stability参数调太低了,50秒内的感情转换得过快,确实有些……情绪不稳定。
并且这个声线给我一种标准的美国年轻白人的感觉,读这份稿子……总有一种……违和感。
单纯从声音角度评价,没有任何不尊重的意思!如有冒犯还请接受我的抱歉!orz
定制自己的AI声线
官网的Voice Lab中支持两种定制方式。
自行调整参数 生成AI声线
Voice Lab提供了三个可选的参数:性别、年龄和口音。除了男性女性、青年中年老年等基本选项外,还支持调节 美国、英国、非洲、澳大利亚、印度五种口音,同时可以通过下方的滑块调整口音的轻重。 输入文本后点击下方的Generate可以生成语音试听效果。免费套餐目前支持生成最多3个AI声线。
直接克隆声音
上传一段超过60秒的语音采样,即可复制说话者的声线。但是这个功能并不包含在免费套餐之内,至少需要订阅初学者套餐。因为本穷学生连饭钱都快没有了,就没有花这个钱。orz
未完待续
接下来探索的项目:
音轨分离:Ultimate Vocal Remover- 歌声音色转换:
so-vits-svc和diff-svc 人造声音模型:ElevenLabs




